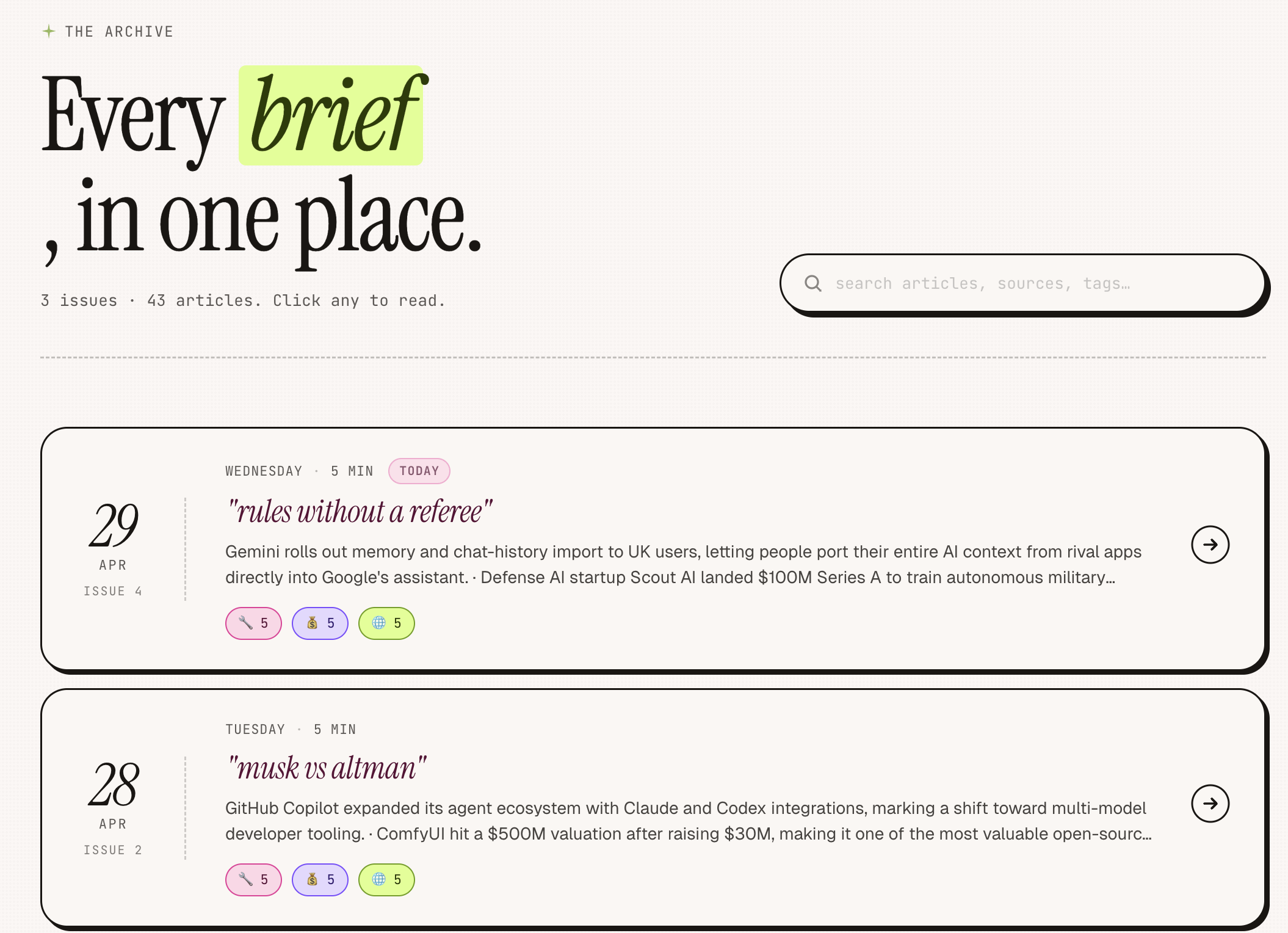
The Newsletter: “by mandy, daily”

Project Description:
A self-running AI newsletter. Every morning it searches the web, synthesizes the top AI stories with Claude, emails them to subscribers, and updates a live searchable archive — automatically.
What I built:
Daily pipeline: Perplexity searches across 3 news categories, Claude synthesizes into a structured digest, Resend delivers it by email, a React web app serves the archive
Semantic search: every article is embedded as a vector locally (no API needed); searching "funding" finds "Series B" and "$40M raise" through meaning, not keyword matching
Hybrid ranking: exact word matches are score-boosted above semantic matches, so the most literal results always surface first
Idempotency guard: the pipeline detects if today's digest already exists and exits cleanly, preventing duplicate runs and duplicate emails
Self-hosted deployment: the pipeline and web server run on a Google Cloud VPS — new digests generate automatically every morning via cron, the FastAPI server stays alive via systemd, and Caddy proxies traffic so the site is publicly accessible without a port number
Technical Experimentation:
Structured output from an LLM
The first real challenge was getting Claude to return consistent, parseable JSON on every run. The solution was a strict schema prompt — explicit field names, fixed enum values, and hard constraints like "return only the JSON object, nothing else." After a few iterations it became reliable enough to wire directly into the pipeline without validation failures.
Prompt caching
The system prompt is the same on every run, so there's no reason to re-process it each time. Sending it with cache_control: ephemeral tells Anthropic's API to hold it in memory for up to 5 minutes, cutting both latency and cost on every daily synthesis call.
Building RAG from scratch
The archive search started as simple keyword matching — fast, but rigid. Searching "funding" would miss any article that said "raised" or "Series B" instead. Replacing it with real retrieval-augmented search meant embedding every article as a vector at generation time, then ranking results by semantic similarity at query time. The embedding model runs entirely locally, so there's no extra API, no extra cost, and no latency on searches.
Hybrid retrieval
Pure semantic search has a subtle flaw: an article with your exact search word in the title can rank below a loosely related one. The fix was a score boost — exact title matches get +0.25, summary matches get +0.12, applied on top of the similarity score. Exact matches always surface first, semantic results follow. This is how production search engines like Elasticsearch handle it.
MCP for live debugging
When the archive broke due to a React rendering error, Claude attempted to connect directly to the running browser tab via MCP — Model Context Protocol — to read the JavaScript console without me having to describe what I was seeing. The Chrome extension wasn't active at that moment so it fell back to reading the source code, but the tooling is wired up for future sessions where Claude can see the browser directly.
Stack
Perplexity · Claude Sonnet · fastembed (local embeddings) · FastAPI · React · Resend · Linux cron · systemd · Caddy · Google Cloud Compute Engine · GitHub